
BigQuery Studio: criando pipelines e rezando pra rodar

O Google Cloud é a melhor e maior cloud do mundo — mas poucos estão prontos para essa conversa.
Hoje, vamos explorar um pouco do BigQuery Workflows — apesar de achar que o Dataform vai de base (ou melhorar).
Mas o intuito aqui é mostrar como funciona. Para isso, criei uma pequena gambiarra — isso mesmo!
Não estou aqui para falar de performance, escalabilidade, melhores práticas… isso é papo de coach/guru (contém ironia — preciso avisar, vai que tem gente que não é nativa de TI).
E vamos precisar dos seguintes requisitos:
Conta no IAM
bucket
tabelas (bronze, silver & gold)
Não vou ensinar como você criar a conta, tabela ou storage — isso aí depois você descobre, né? Hahaha!
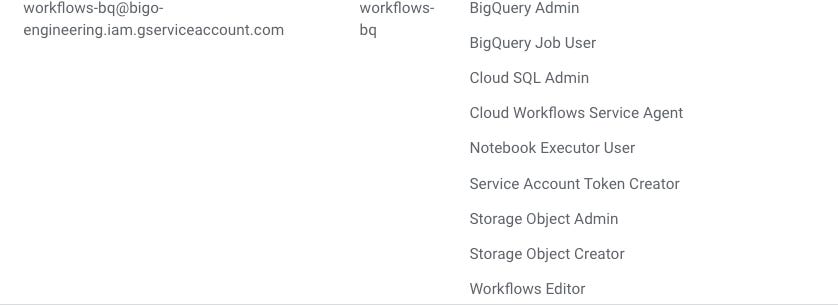
Para adicionar uma nova regra, você pode editar a conta e adicioná-la. Veja só:
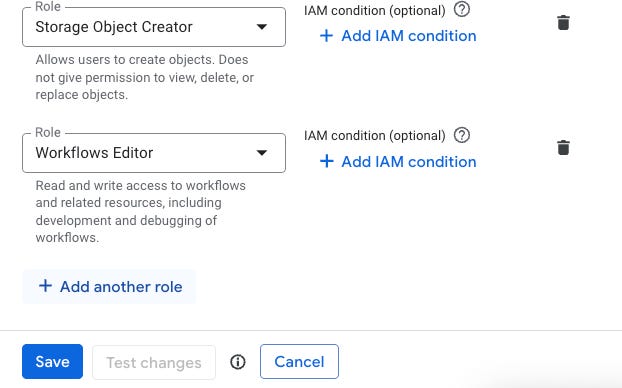
E um storage
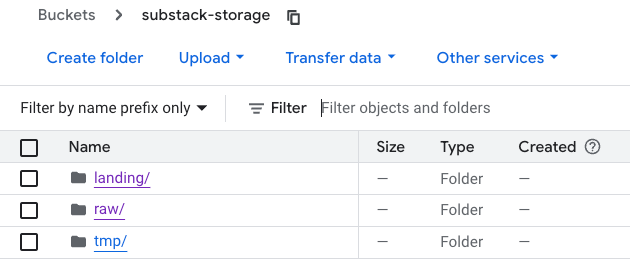
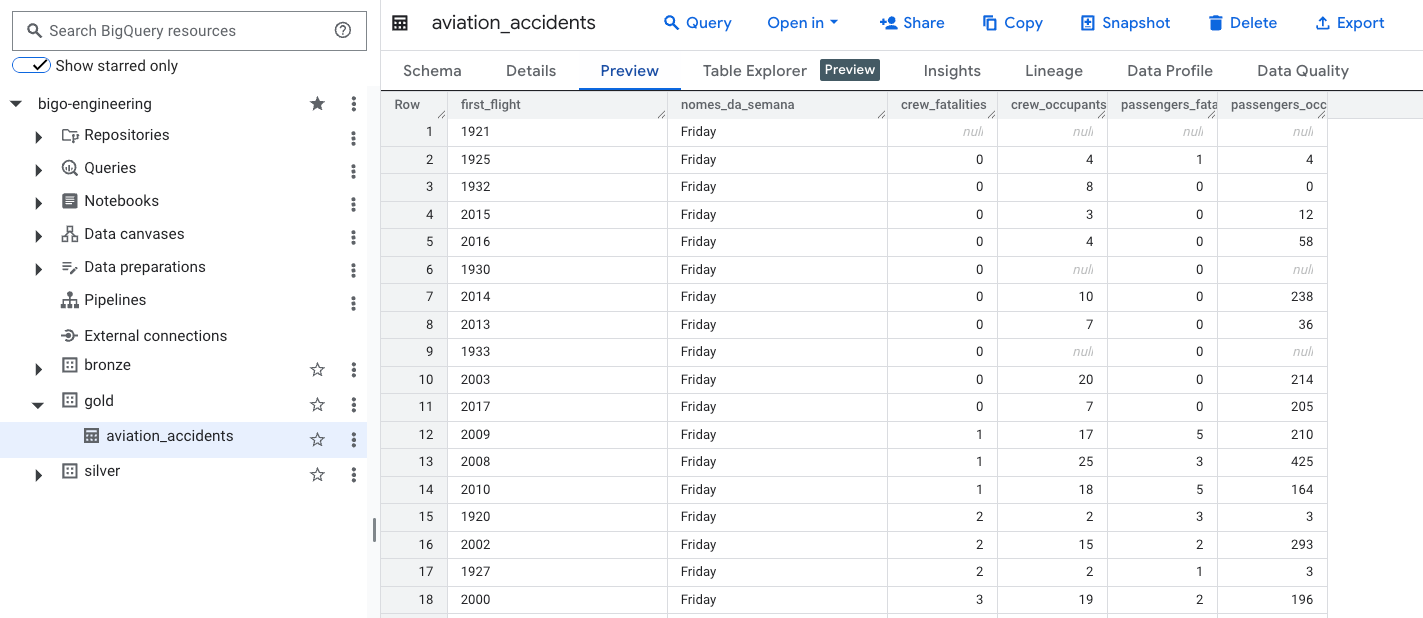
E esta é a minha estrutura no BigQuery.

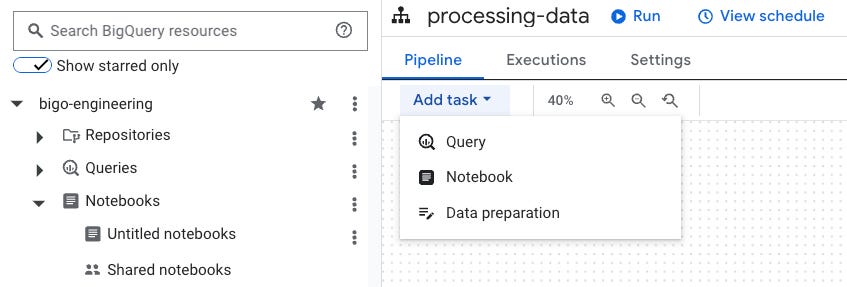
Sem muitos segredos, agora vá em Pipelines e crie um novo. Melhor clicar ali onde você seleciona a ação que quer fazer.
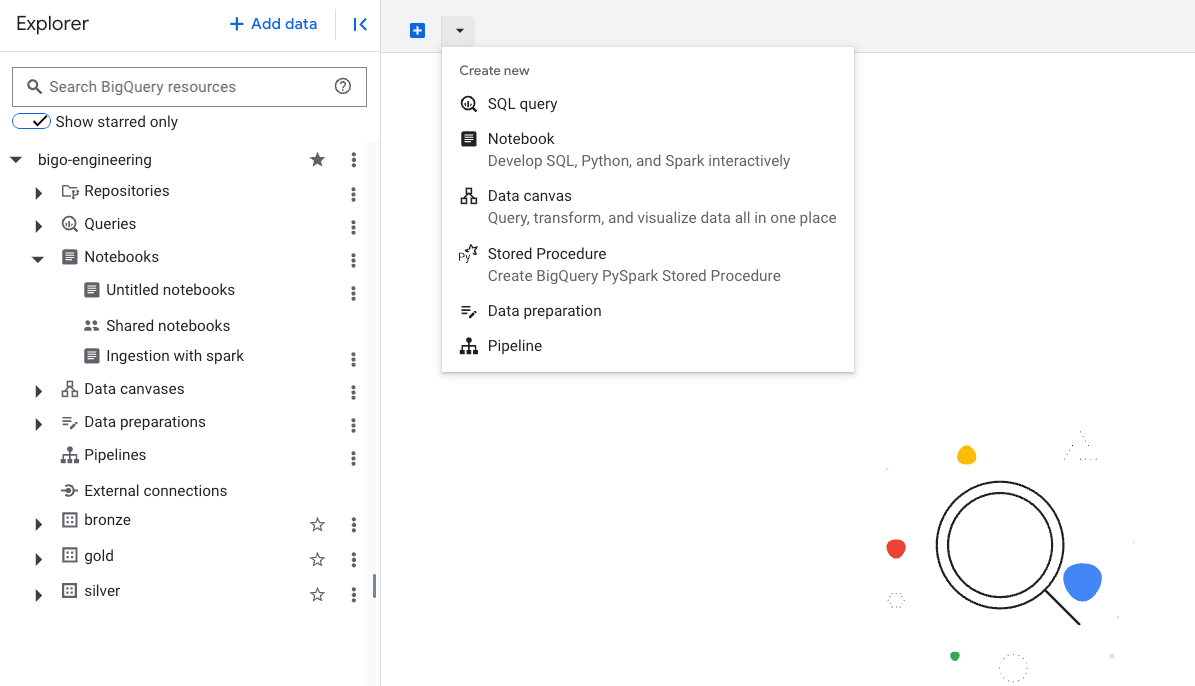
Clique em Pipeline, dê um nome para ele, depois selecione o tipo de task:
Query: query comum para criar uma transformação usando SQL
Notebook: notebook Colab para usar libs comuns como pandas, bigframes, etc.
Data Preparation: criar transformação usando linguagem natural
Esse é o mesmo pipeline — calma que eu vou explicar tudo.
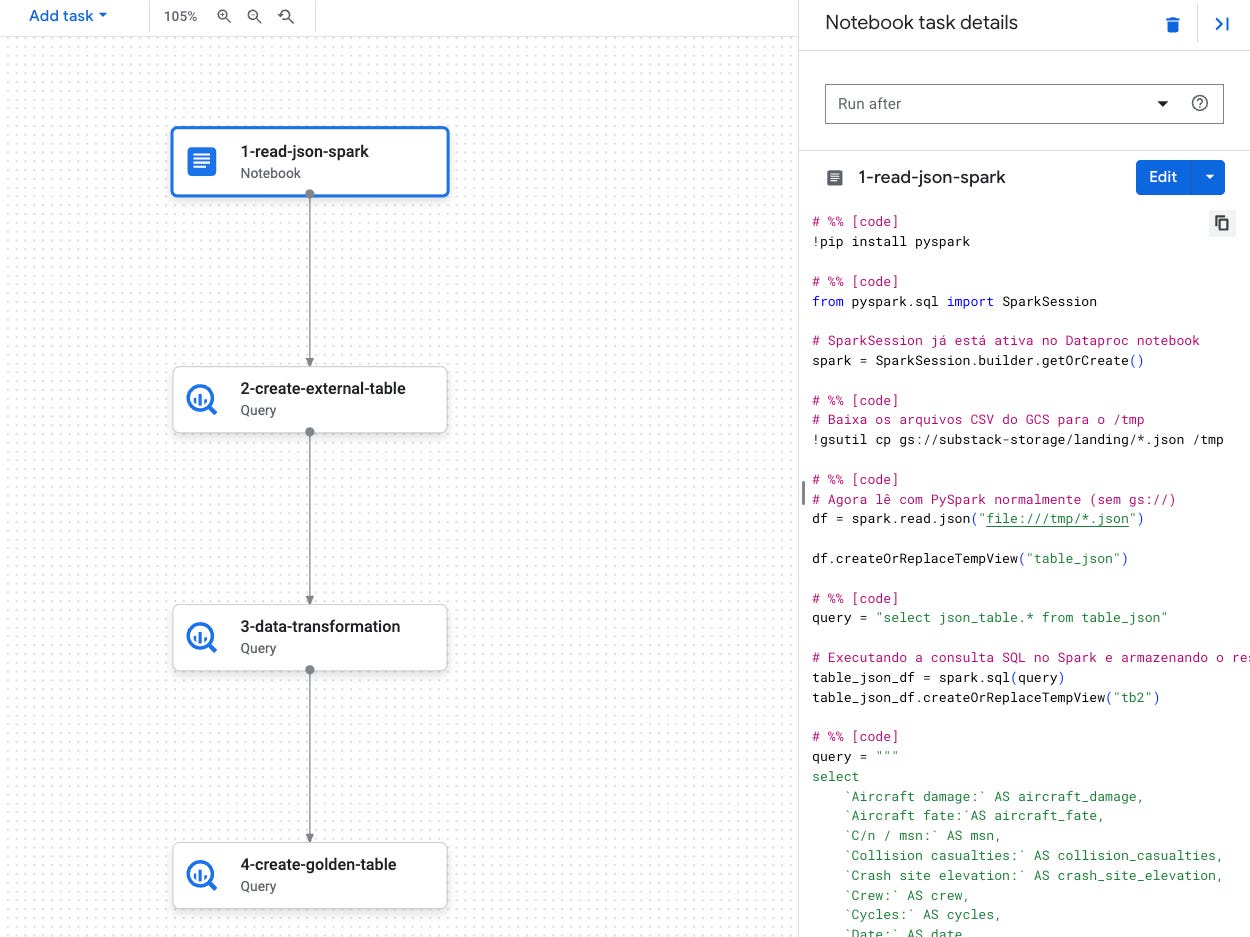
Aqui tem um ponto importante: você pode criar o seu notebook separado e depois linká-lo ao pipeline. Veja só:
Adicionei 1 notebook

Ou você vai em Edit Notebook, ou pode importar um já existente, clicando em Import a Copy. Assim, você seleciona a cópia de um notebook existente.
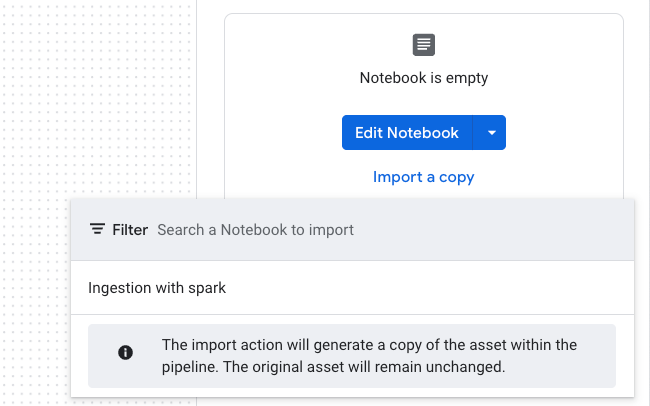
Esse è o meu notebook
Clicando em Edit do lado direito, você coloca o notebook em edição — óbvio, pqp. 😅
Aqui começa a minha admirável gambiarra — excelente, hahaha!
Descrição do código abaixo:
Instalação do PySpark
Criação de pasta tmp local (novo processo não lê os dados do GCS direto)
Leitura de arquivo baixado da landing do bucket falado acima
Processamento do arquivo: limpeza, filtragem, etc. — todos os ajustes necessários
Escrita local em Parquet
Upload de dados para a Raw
!pip install pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
!gsutil cp gs://substack-storage/landing/*.json /tmp
# Agora lê com PySpark normalmente (sem gs://)
df = spark.read.json("file:///tmp/*.json")
df.createOrReplaceTempView("table_json")
query = "select json_table.* from table_json"
# Executando a consulta SQL no Spark e armazenando o resultado em um DataFrame.
table_json_df = spark.sql(query)
table_json_df.createOrReplaceTempView("tb2")
query = """
select
`Aircraft damage:` AS aircraft_damage,
`Aircraft fate:`AS aircraft_fate,
`C/n / msn:` AS msn,
`Collision casualties:` AS collision_casualties,
`Crash site elevation:` AS crash_site_elevation,
`Crew:` AS crew,
`Cycles:` AS cycles,
`Date:` AS date,
`Departure airport:` AS departure_airport,
`Destination airport:` AS destination_airport,
`Engines:` AS engines,
`First flight:` AS first_flight,
`Flightnumber:` AS flightnumber,
`Ground casualties:` AS ground_casualties,
`Leased from:` AS leased_from,
`Location:` AS location,
`Nature:` AS nature,
`On behalf of:` AS on_behalf_of,
`Operated by:` AS operated_by,
`Operating for:` AS operating_for,
`Operator:` AS operator,
`Passengers:` AS passengers,
`Phase:` AS phase,
`Registration:` AS registration,
`Status:` AS status,
`Time:` AS time,
`Total airframe hrs:` AS total_airframe_hrs,
`Total:` AS total,
`Type:` AS type,
`json_cleaned` AS json_cleaned
from
tb2
"""
# renomeia as colunas
padroniza_colunas_df = spark.sql(query)
# esclusao de dados local
!rm -rf /tmp/stg
# escrita de dados
padroniza_colunas_df.write.format("parquet").mode("overwrite").save("file:///tmp/stg/")
# upload de dados
!gsutil cp file:///tmp/stg/*.parquet gs://substack-storage/raw
# kill spark
spark.stop()Apos processar e enviar os arquivos para a raw
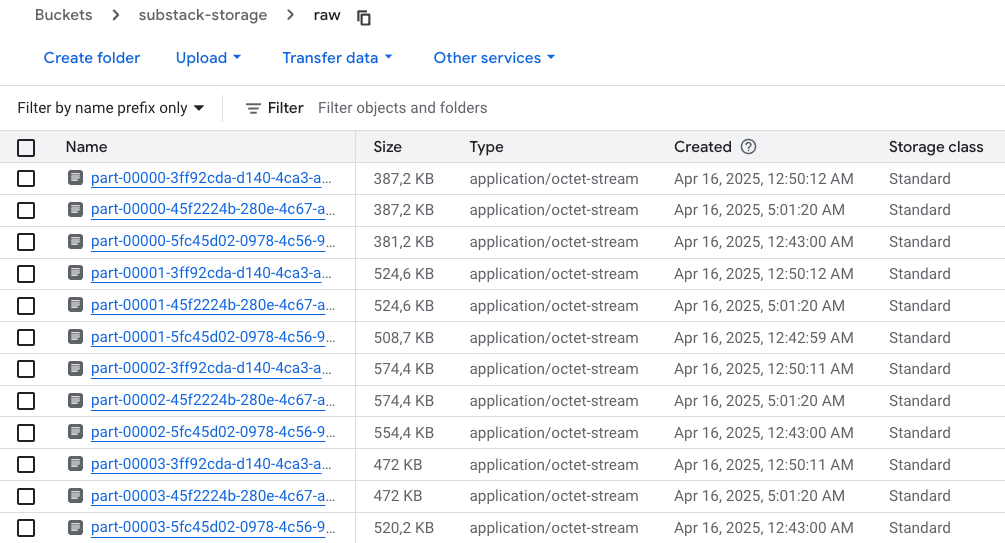
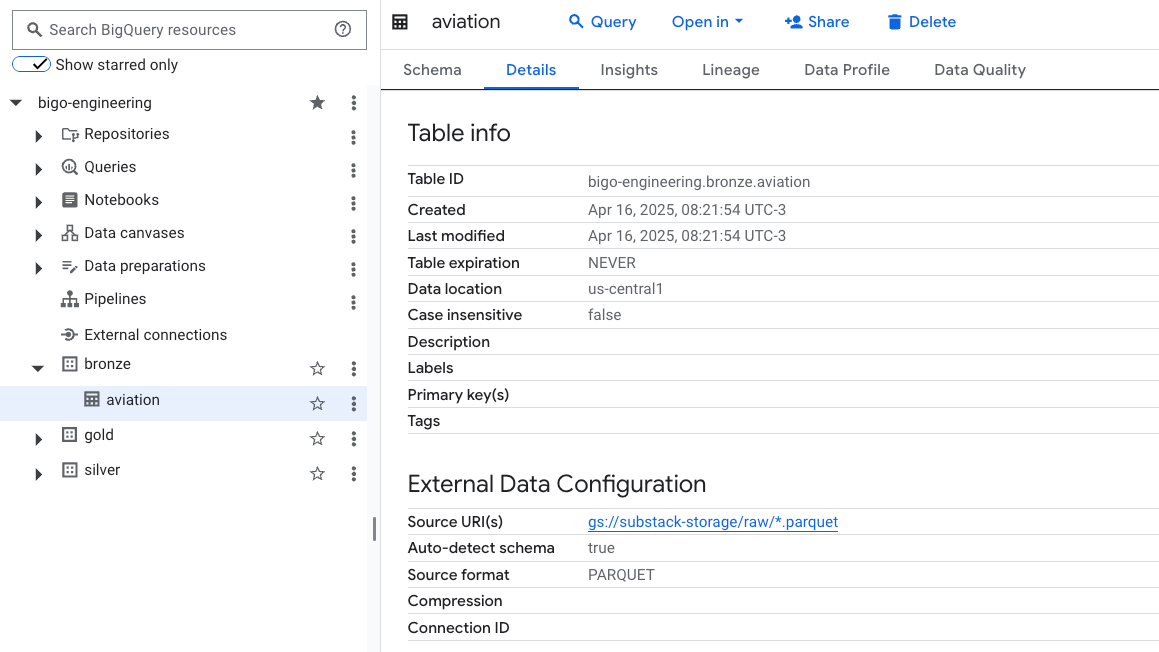
Próximo passo: criar uma tabela externa no BigQuery.

Descrição do código abaixo:
Verifica se a tabela existe no information_schema
Se existir, faz a exclusão da mesma
Cria a tabela, apontando para os arquivos Parquet na Raw
DECLARE table_exists BOOL;
-- Verifica se a tabela externa existe
SET table_exists = (
SELECT COUNT(*) > 0
FROM `bigo-engineering.bronze.INFORMATION_SCHEMA.TABLES`
WHERE table_name = 'aviation'
);
-- Se a tabela existir, deleta
IF table_exists THEN
DROP EXTERNAL TABLE `bigo-engineering.bronze.aviation`;
END IF;
CREATE OR REPLACE EXTERNAL TABLE `bigo-engineering.bronze.aviation`
OPTIONS (
format = 'PARQUET',
uris = ['gs://substack-storage/raw/*.parquet']
);Proximo passo

Descrição do código abaixo:
Merge de dados - crie a estrutura da tabela antes
Cria coluna de dia da semana
Cria coluna de nome do mês
Concatena campos de datas
Atualiza/Insere dados
Esse Merge está pela metade, faltam campos no ON para uma melhor verificação e validação dos campos.
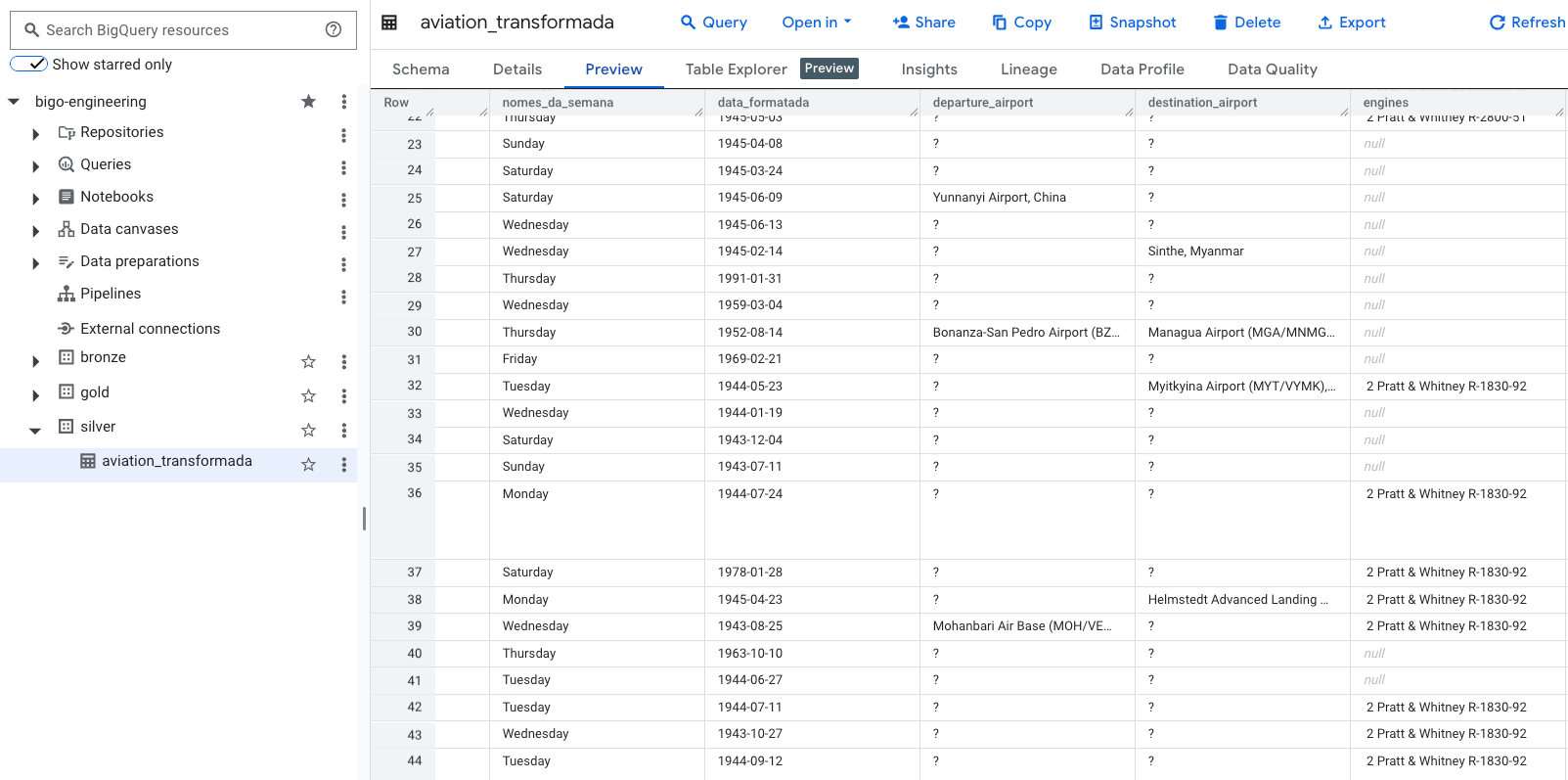
MERGE `bigo-engineering.silver.aviation_transformada` AS target
USING (
WITH table_load AS (
SELECT
aircraft_damage,
aircraft_fate,
msn,
collision_casualties,
crash_site_elevation,
SAFE_CAST(SPLIT(SPLIT(crew, '/')[SAFE_OFFSET(0)], ':')[SAFE_OFFSET(1)] AS INT64) AS crew_fatalities,
SAFE_CAST(SPLIT(SPLIT(crew, '/')[SAFE_OFFSET(1)], ':')[SAFE_OFFSET(1)] AS INT64) AS crew_occupants,
SAFE_CAST(cycles AS INT64) AS cycles,
date,
departure_airport,
destination_airport,
engines,
first_flight,
flightnumber,
ground_casualties,
leased_from,
location,
nature,
on_behalf_of,
operated_by,
operating_for,
operator,
SAFE_CAST(SPLIT(SPLIT(passengers, '/')[SAFE_OFFSET(0)], ':')[SAFE_OFFSET(1)] AS INT64) AS passengers_fatalities,
SAFE_CAST(SPLIT(SPLIT(passengers, '/')[SAFE_OFFSET(1)], ':')[SAFE_OFFSET(1)] AS INT64) AS passengers_occupants,
phase,
registration,
status,
time,
SAFE_CAST(total_airframe_hrs AS FLOAT64) AS total_airframe_hrs,
SAFE_CAST(SPLIT(SPLIT(total, '/')[SAFE_OFFSET(0)], ':')[SAFE_OFFSET(1)] AS INT64) AS total_fatalities,
SAFE_CAST(SPLIT(SPLIT(total, '/')[SAFE_OFFSET(1)], ':')[SAFE_OFFSET(1)] AS INT64) AS total_occupants,
type,
json_cleaned
FROM `bigo-engineering.bronze.aviation`
),
table_filter AS (
SELECT *
FROM table_load
WHERE ARRAY_LENGTH(SPLIT(date, ' ')) >= 4
),
table_slices AS (
SELECT
*,
SPLIT(date, ' ')[SAFE_OFFSET(0)] AS nomes_da_semana,
IF(LENGTH(SPLIT(date, ' ')[SAFE_OFFSET(1)]) = 1,
CONCAT('0', SPLIT(date, ' ')[SAFE_OFFSET(1)]),
SPLIT(date, ' ')[SAFE_OFFSET(1)]) AS dia_na_semana,
SPLIT(date, ' ')[SAFE_OFFSET(2)] AS mes_na_semana,
SPLIT(date, ' ')[SAFE_OFFSET(3)] AS ano
FROM table_filter
),
table_slices_mes AS (
SELECT *,
CASE
WHEN mes_na_semana = 'January' THEN '01'
WHEN mes_na_semana = 'February' THEN '02'
WHEN mes_na_semana = 'March' THEN '03'
WHEN mes_na_semana = 'April' THEN '04'
WHEN mes_na_semana = 'May' THEN '05'
WHEN mes_na_semana = 'June' THEN '06'
WHEN mes_na_semana = 'July' THEN '07'
WHEN mes_na_semana = 'August' THEN '08'
WHEN mes_na_semana = 'September' THEN '09'
WHEN mes_na_semana = 'October' THEN '10'
WHEN mes_na_semana = 'November' THEN '11'
WHEN mes_na_semana = 'December' THEN '12'
END AS mes_na_semana_final
FROM table_slices
),
table_cancatena_tudo AS (
SELECT *,
CONCAT(ano, '-', mes_na_semana_final, '-', dia_na_semana) AS data_final_str
FROM table_slices_mes
),
deduplicated_source AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY registration ORDER BY SAFE.PARSE_DATE('%Y-%m-%d', data_final_str) DESC) AS row_num
FROM table_cancatena_tudo
)
SELECT
CAST(aircraft_damage AS STRING) AS aircraft_damage,
CAST(aircraft_fate AS STRING) AS aircraft_fate,
CAST(crew_fatalities AS STRING) AS crew_fatalities,
CAST(crew_occupants AS STRING) AS crew_occupants,
CAST(nomes_da_semana AS STRING) AS nomes_da_semana,
FORMAT_DATE('%Y-%m-%d', SAFE.PARSE_DATE('%Y-%m-%d', data_final_str)) AS data_formatada,
CAST(departure_airport AS STRING) AS departure_airport,
CAST(destination_airport AS STRING) AS destination_airport,
CAST(engines AS STRING) AS engines,
CAST(SAFE_CAST(SUBSTR(TRIM(first_flight), 1, 4) AS INT64) AS STRING) AS first_flight,
CAST(location AS STRING) AS location,
CAST(nature AS STRING) AS nature,
CAST(operator AS STRING) AS operator,
CAST(passengers_fatalities AS STRING) AS passengers_fatalities,
CAST(passengers_occupants AS STRING) AS passengers_occupants,
CAST(phase AS STRING) AS phase,
CAST(registration AS STRING) AS registration,
CAST(status AS STRING) AS status,
CAST(TRIM(REPLACE(REPLACE(REPLACE(time, 'ca', ''), '.', ''), 'UTC', '')) AS STRING) AS time,
CAST(total_fatalities AS STRING) AS total_fatalities,
CAST(total_occupants AS STRING) AS total_occupants,
CAST(type AS STRING) AS type,
CAST(SAFE_CAST(SUBSTR(TRIM(first_flight), 1, 4) AS INT64) AS STRING) AS _first_flight
FROM deduplicated_source
WHERE row_num = 1 -- Seleciona apenas a primeira linha de cada grupo de duplicatas
) AS source
ON target.registration = source.registration
-- Atualiza os registros existentes
WHEN MATCHED THEN
UPDATE SET
target.aircraft_damage = source.aircraft_damage,
target.aircraft_fate = source.aircraft_fate,
target.crew_fatalities = source.crew_fatalities,
target.crew_occupants = source.crew_occupants,
target.nomes_da_semana = source.nomes_da_semana,
target.data_formatada = source.data_formatada,
target.departure_airport = source.departure_airport,
target.destination_airport = source.destination_airport,
target.engines = source.engines,
target.first_flight = source.first_flight,
target.location = source.location,
target.nature = source.nature,
target.operator = source.operator,
target.passengers_fatalities = source.passengers_fatalities,
target.passengers_occupants = source.passengers_occupants,
target.phase = source.phase,
target.status = source.status,
target.time = source.time,
target.total_fatalities = source.total_fatalities,
target.total_occupants = source.total_occupants,
target.type = source.type,
target._first_flight = source._first_flight
-- Insere novos registros
WHEN NOT MATCHED THEN
INSERT (
aircraft_damage,
aircraft_fate,
crew_fatalities,
crew_occupants,
nomes_da_semana,
data_formatada,
departure_airport,
destination_airport,
engines,
first_flight,
location,
nature,
operator,
passengers_fatalities,
passengers_occupants,
phase,
registration,
status,
time,
total_fatalities,
total_occupants,
type,
_first_flight
)
VALUES (
source.aircraft_damage,
source.aircraft_fate,
source.crew_fatalities,
source.crew_occupants,
source.nomes_da_semana,
source.data_formatada,
source.departure_airport,
source.destination_airport,
source.engines,
source.first_flight,
source.location,
source.nature,
source.operator,
source.passengers_fatalities,
source.passengers_occupants,
source.phase,
source.registration,
source.status,
source.time,
source.total_fatalities,
source.total_occupants,
source.type,
source._first_flight
);E por fim
Descrição do código abaixo:
Cria ou substitui a tabela
Agrupa valores por primeiro voo e nomes da semana
CREATE OR REPLACE TABLE `bigo-engineering.gold.aviation_accidents` AS
SELECT
first_flight,
nomes_da_semana,
SUM(CAST(crew_fatalities AS INT64)) AS crew_fatalities,
SUM(CAST(crew_occupants AS INT64)) AS crew_occupants,
SUM(CAST(passengers_fatalities AS INT64)) AS passengers_fatalities,
SUM(CAST(passengers_occupants AS INT64)) AS passengers_occupants
FROM
`bigo-engineering.silver.aviation_transformada`
WHERE
first_flight IS NOT NULL
GROUP BY
first_flight,
nomes_da_semanaPara executar o pipeline, você pode fazer de forma manual ou agendada. Veja:
Clique em Run.
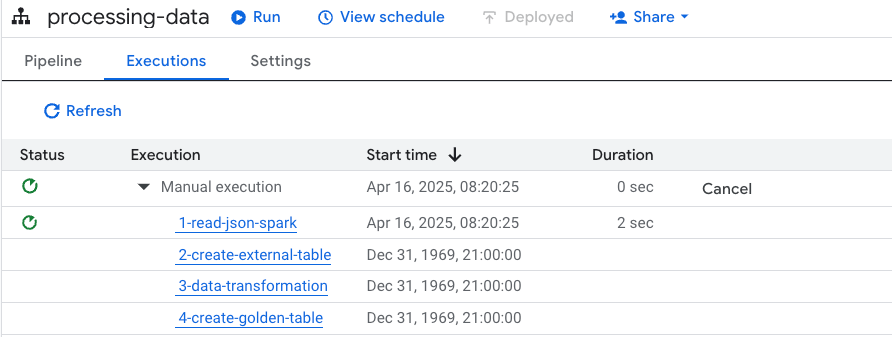
Mas antes de executar, vá em Settings para definir a computação.
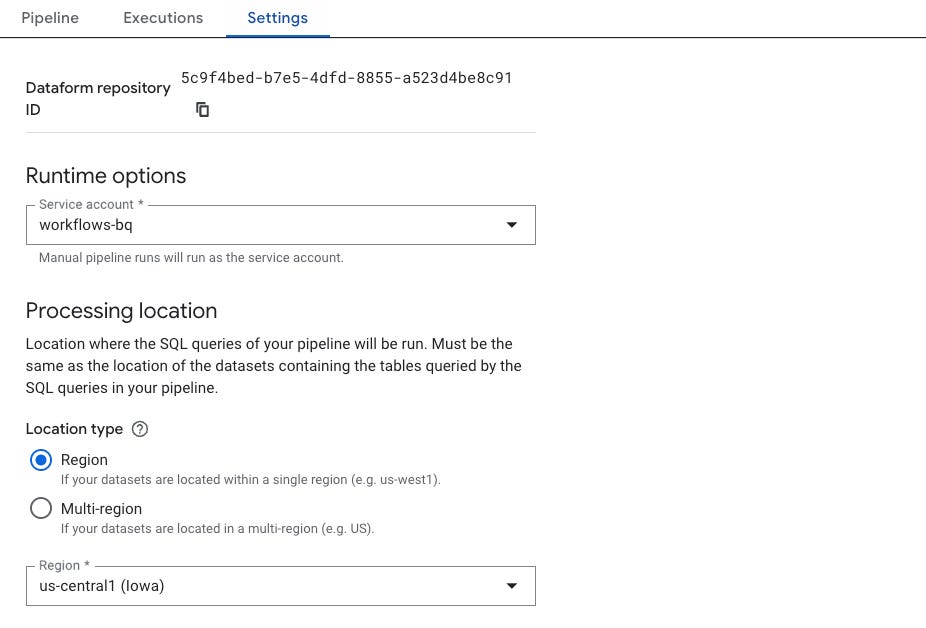
Defina:
Chave de serviço: usada para autenticar o pipeline com permissões adequadas
Região: onde os recursos do pipeline serão executados (ex: us-central1, europe-west1, etc.)
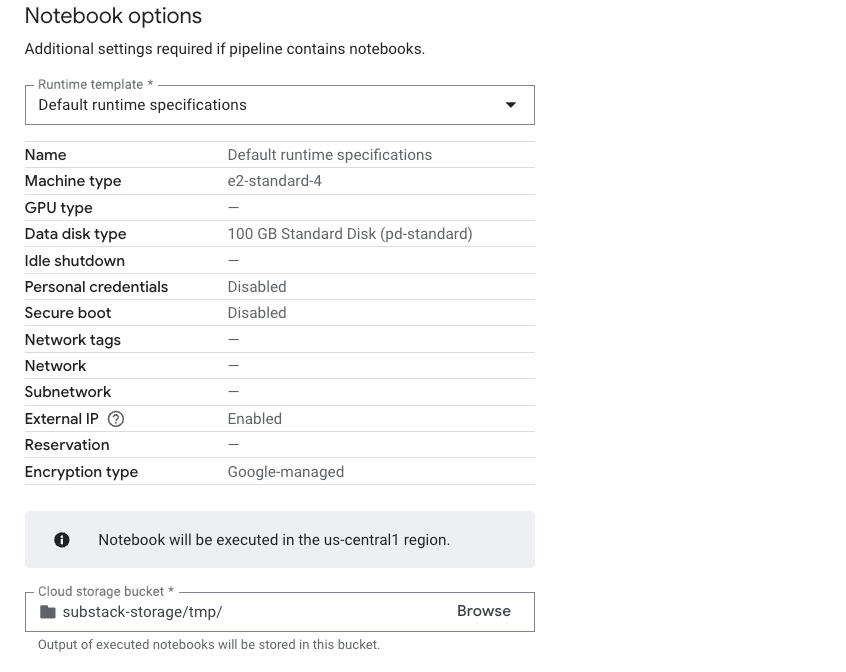
Tipo de runtime — ainda não vi como criar um novo, acho que isso é gerenciado automaticamente.
Runtime
Bucket: a maioria dos serviços usa buckets temporários para processar arquivos.
Após a execução, temos o seguinte:
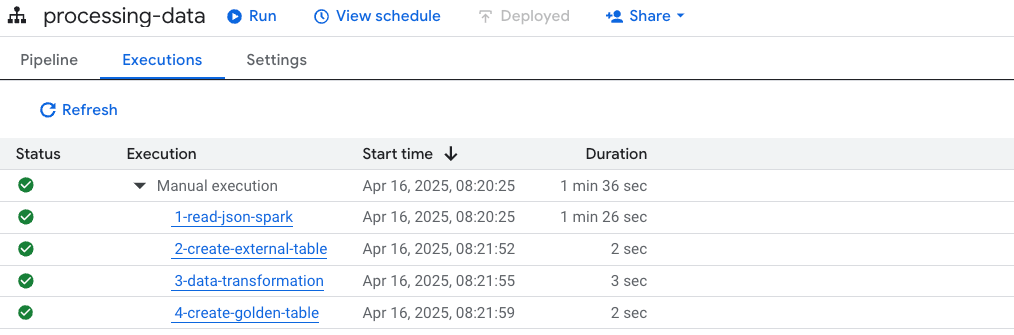
Artefatos gerados:
2-create-external-table
3-data-transformation
4-create-golden-table
Nao esquecendo, caso queira a execucao automatica, va em
E defina as configurações de execução — achou que eu ia te ensinar a criar? 🤡 Se vire!
Brincadeiras à parte, tem alguns pontos que acredito que o Google ainda esteja trabalhando:
Ainda não é possível mover as tasks para organizar o pipeline — tá tudo na vertical mesmo
Acho que não tem link com o Repositories
Não dá pra plugar o notebook no Dataproc Serverless (acho que viajei aqui… sei lá)
Enfim, quis trazer esse pequeno exemplo bem mal feito. Bye!