
🧵 DAG bonita não entrega dado. Rundeck sim, Orquestrando jobs spark com o mesmo

Às vezes, o que parece “feio” é só mais eficiente.
Enquanto uns ficam admirando a UI do Airflow,
o Rundeck já terminou o job e reiniciou o serviço do cluster com sucesso.
Sem glamour. Só entrega.
Bem-vindo a este local onde destilo um percentual mínimo de tudo o que conheço sobre tecnologia e afins. Hoje vamos falar sobre orquestração de pipeline de dados. Lembre-se: aqui eu não ensino boas práticas de nada, e não tenho interesse em ensinar nada a você — tenha ciência disso. O que faço aqui é puramente compartilhar conhecimento prático com uma pitada de humor negro.
Então vamos ao que interessa: eu odeio o Apache Airflow. Tanto que posso afirmar saber muito mais do que você sobre ele — talvez por já ter usado em grandes projetos e ter sugado ao máximo tudo o que ele tinha a oferecer. Afinal, só se pode falar mal do que se conhece de verdade.
Rundeck é uma solução de automação incrível e bem simples. Tão simples que podemos chamá-lo de loucoder — tem que ser muito maluco pra usar, hahahaha! Mas é amado (e por vezes carinhosamente chamado de Rundekinho) pela galera raiz de infra (DevOps).
Para usar, não tem segredo: funciona em qualquer Linux, Windows e macOS. O meu, por exemplo, eu baixei no meu modesto ambiente (macOS com chip M3 Max — hahahahaha). Só precisei baixar um arquivo .war (porque com Java, só se resolve na base do .war, hahahaha). O comando é bem simples.
java -Xmx1024m -Xms256m -jar rund.warno browser escreva localhost:4440
user:admin
pass:admin
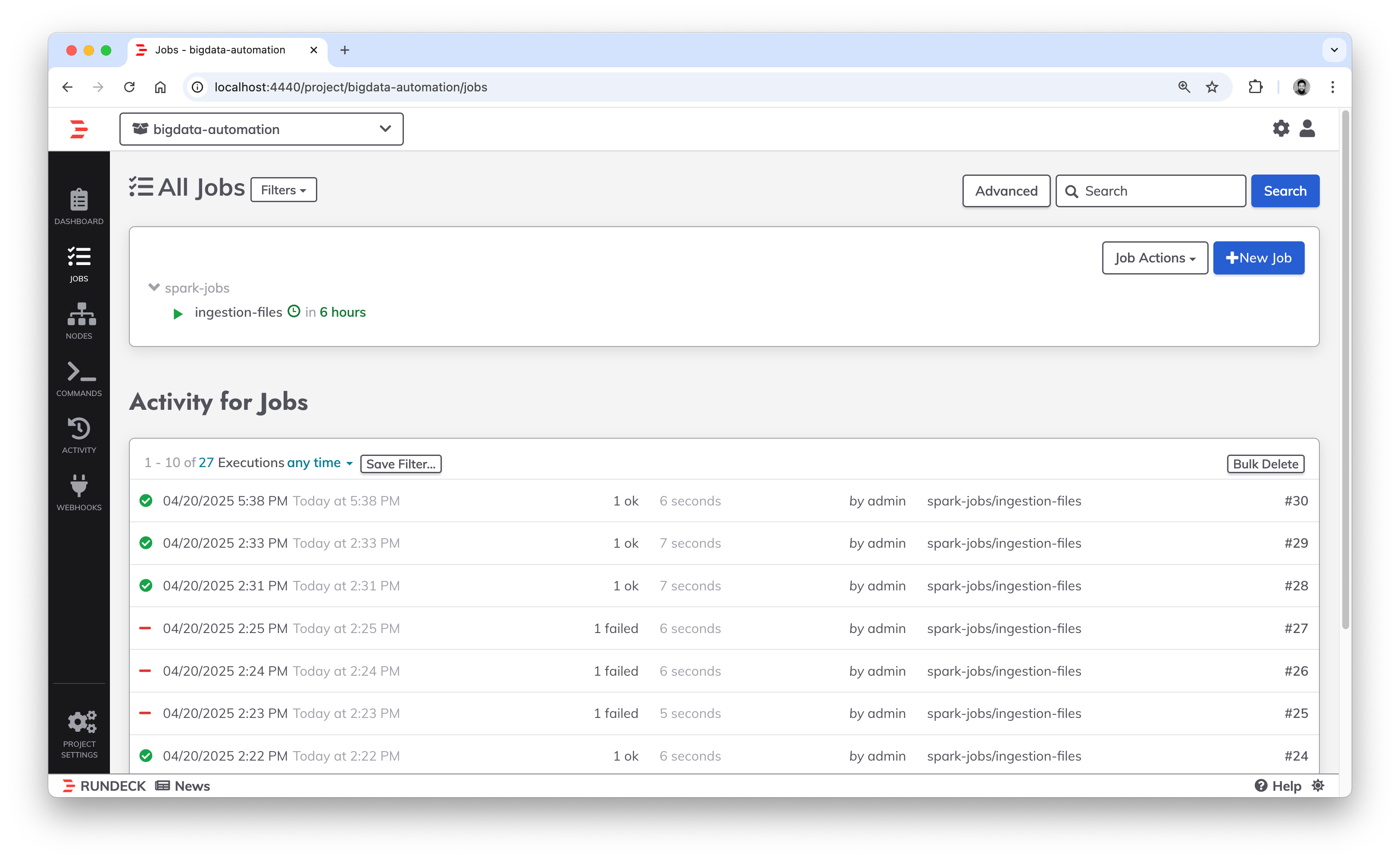
Aqui eu criei um projetinho simples
Va direto para jobs e crie um novo job
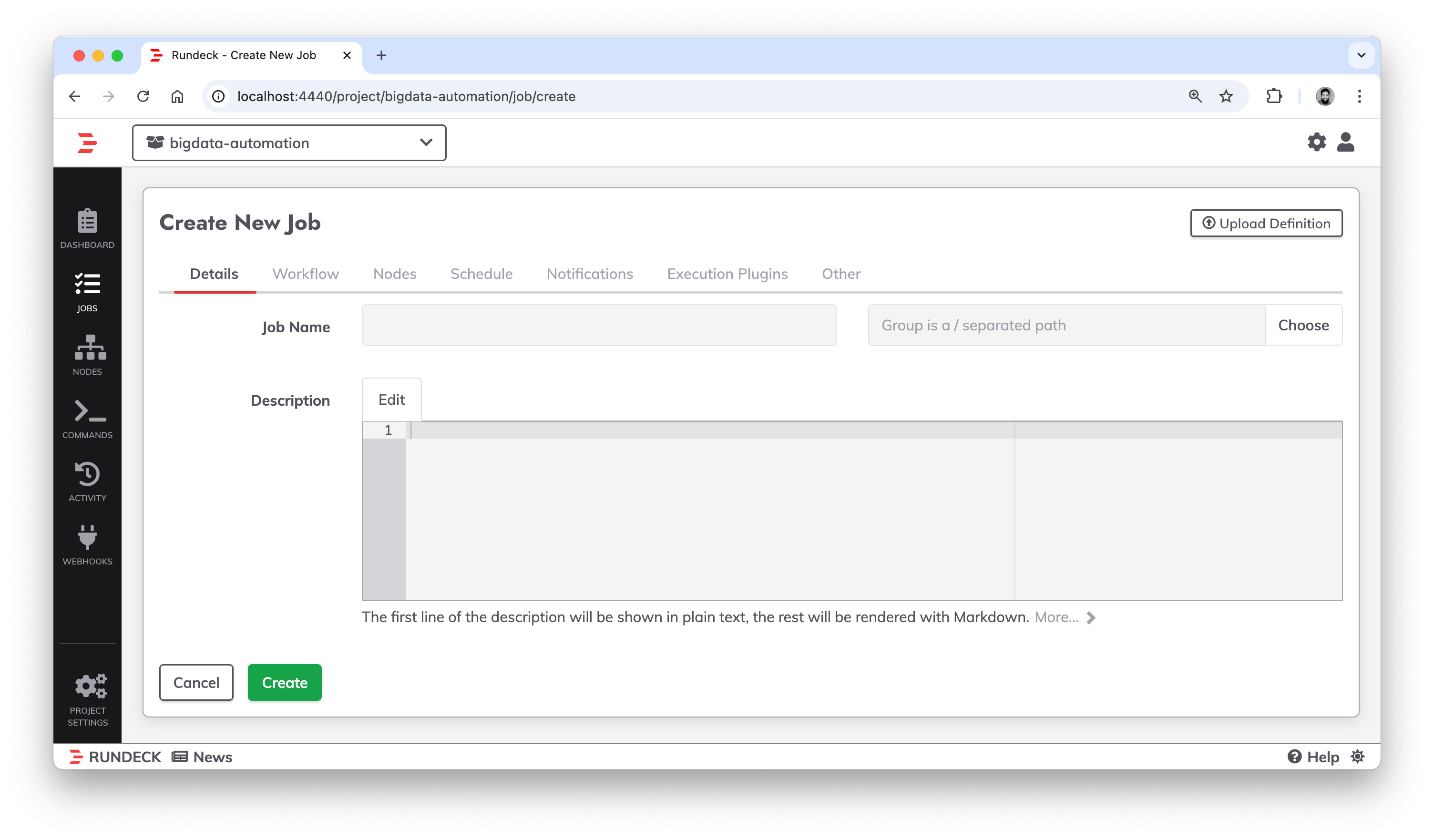
Uma Breve explicacao das configs do job
Definicoes de nome do job
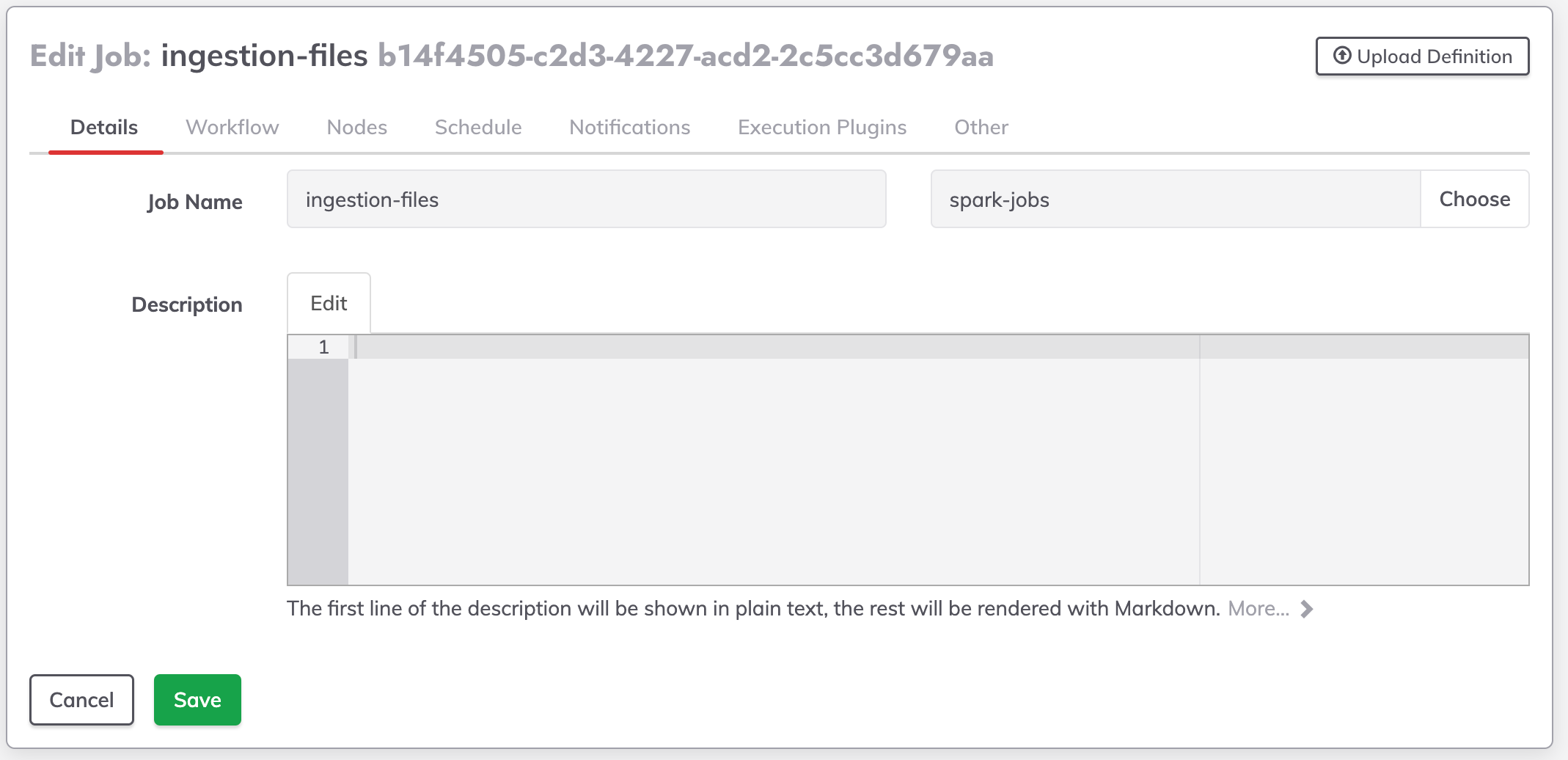
Definicao de steps e estrategia de execucao (paralela, sequencia e node first)
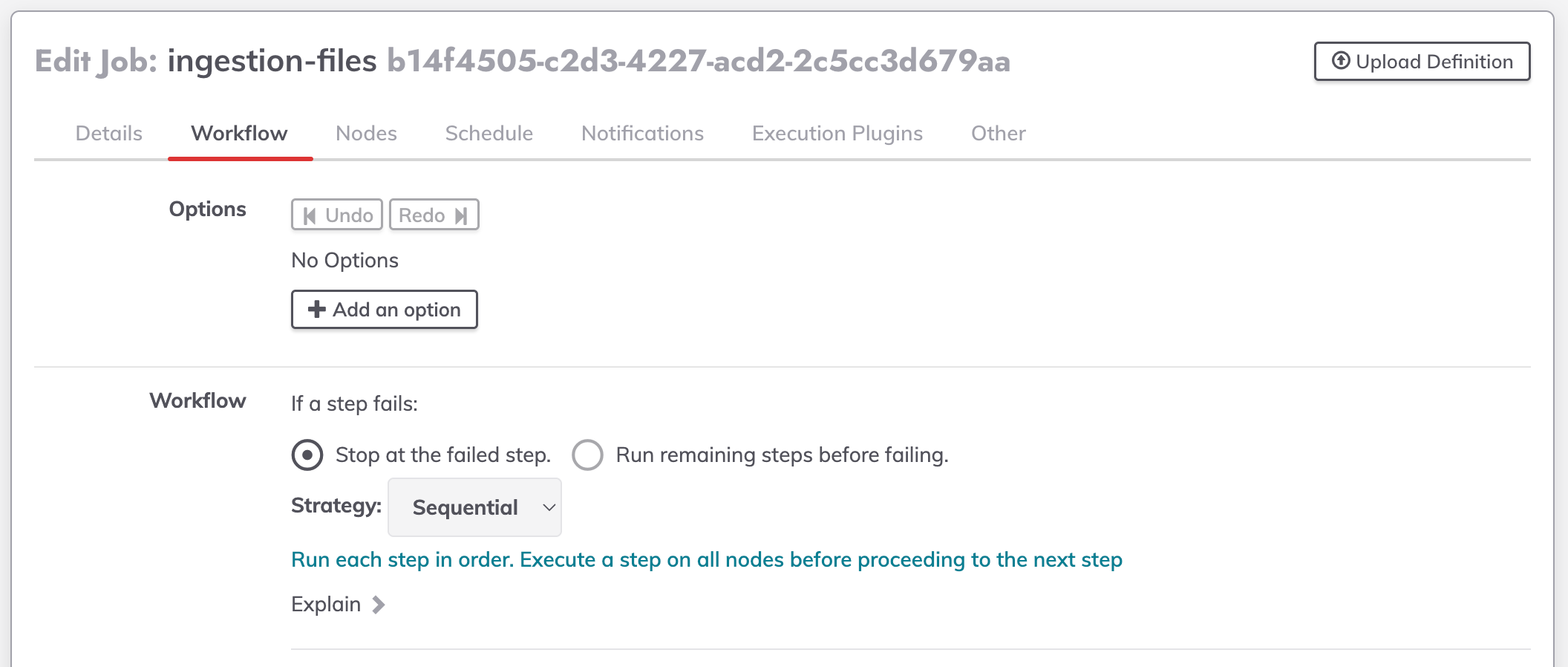
programacao de execucao
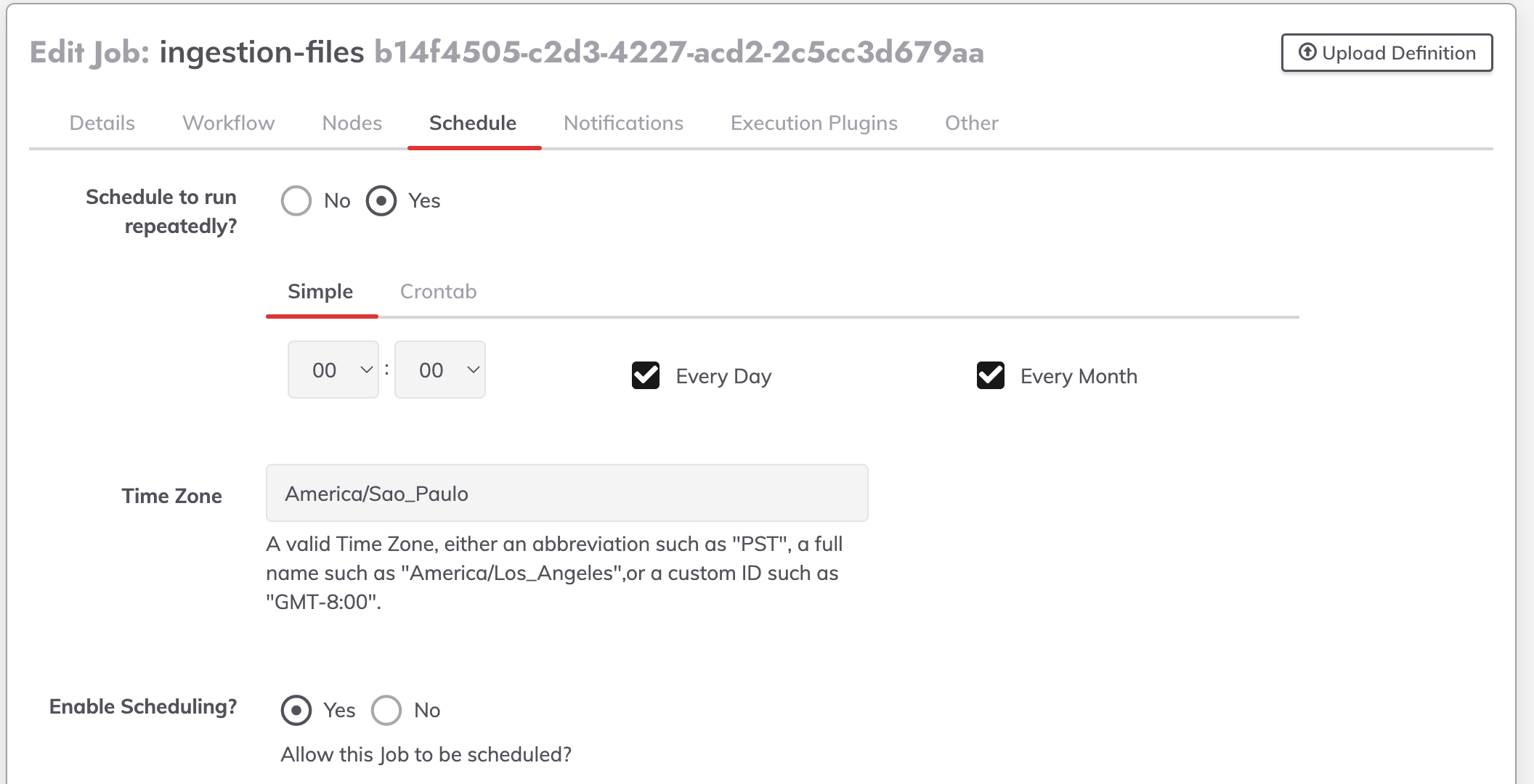
Notificacoes (Airflow chora nisso)
Vamos à criação e execução. Aqui temos duas formas de criar: manual ou via API. Neste caso, vou fazer via API.
Esse è o YAML que uso
- defaultTab: output
description: ''
executionEnabled: true
group: spark-jobs
id: b14f4505-c2d3-4227-acd2-2c5cc3d679aa
loglevel: INFO
name: ingestion-files
nodeFilterEditable: false
notification:
onfailure:
email:
attachType: file
recipients: romeritomorais@outlook.com.br
subject: rundeck
notifyAvgDurationThreshold: null
plugins:
ExecutionLifecycle: null
schedule:
month: '*'
time:
hour: '00'
minute: '00'
seconds: '0'
weekday:
day: '*'
year: '*'
scheduleEnabled: true
sequence:
commands:
- description: convert notebook
exec: source /Users/romeritomorais/Documents/Develop/pyenv/ev@311/bin/Activate &&
jupyter nbconvert --to script /Users/romeritomorais/Documents/Develop/spark/src/notebook/load-files.ipynb
--output-dir=/Users/romeritomorais/Documents/Develop/spark/src/scripts
- description: load data
exec: spark-submit --master "local[*]" /Users/romeritomorais/Documents/Develop/spark/src/scripts/load-files.py
- description: list files
exec: ls -lha /Users/romeritomorais/Documents/Develop/spark/s3/raw/file
keepgoing: false
strategy: sequential
timeZone: America/Sao_Paulo
uuid: b14f4505-c2d3-4227-acd2-2c5cc3d679aa
com o codigo acima vc pode enviar por esse botao

ou via comando no shell
#!/bin/bash
curl -X POST \
-H "Content-Type: application/yaml" \
-H "Accept: application/json" \
-H "X-Rundeck-Auth-Token: SbFsMwy6Er0vupSQh1fGdV4QjzUTSKMV" \
--data-binary @ingestion-files.yaml \
"http://localhost:4440/api/40/project/bigdata-automation/jobs/import?dupeOption=update"Para isso voce precisa criar um TOKEN e adicionar aqui
"X-Rundeck-Auth-Token: COLE AQUI"Va em profile e crie o token
Aqui o resultado da execucao
{
"succeeded":[
{
"index":1,
"href":"http://localhost:4440/api/52/job/b14f4505-c2d3-4227-acd2-2c5cc3d679aa",
"id":"b14f4505-c2d3-4227-acd2-2c5cc3d679aa",
"name":"ingestion-files",
"group":"spark-jobs",
"project":"bigdata-automation",
"permalink":"http://localhost:4440/project/bigdata-automation/job/show/b14f4505-c2d3-4227-acd2-2c5cc3d679aa"
}
],
"failed":[
],
"skipped":[
Job enviado
Vamos explorar as configuracoes
No modo de edicao temos os steps do nosso job
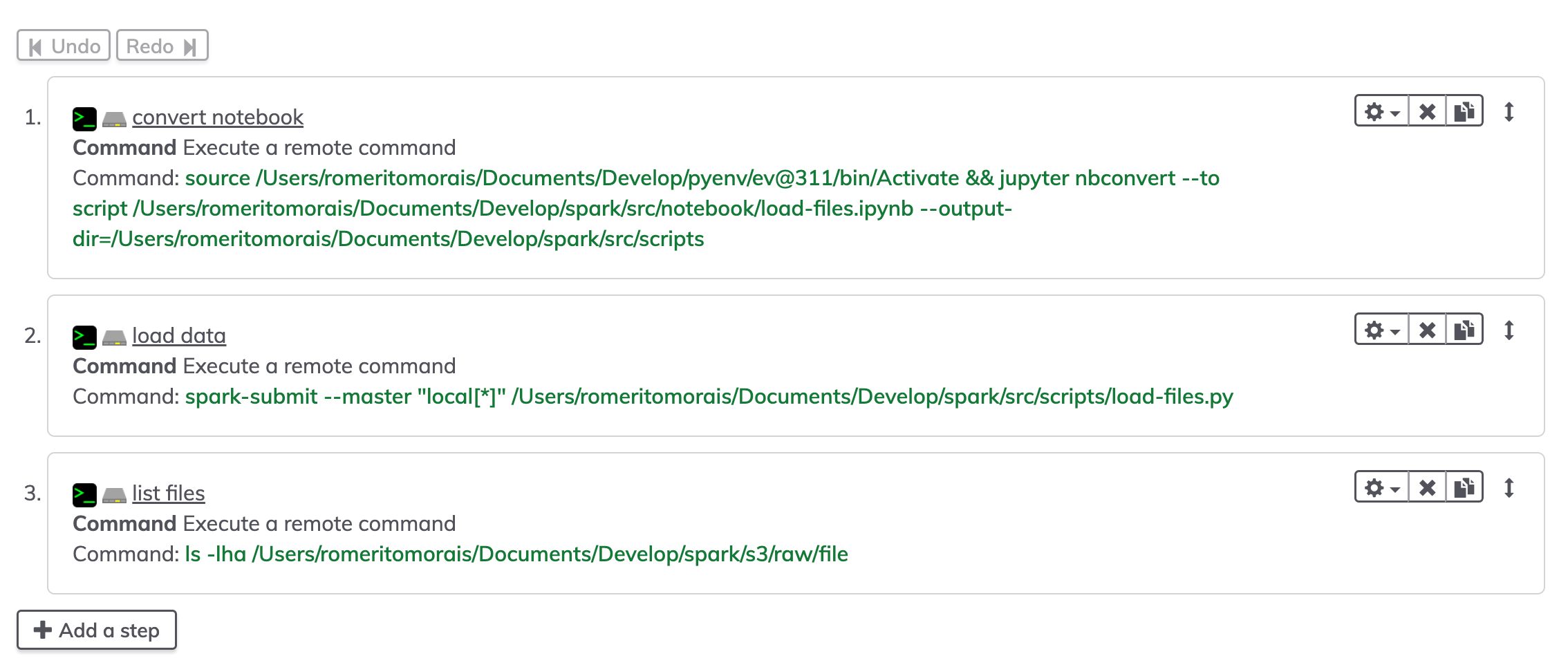
Aqui escolhi executar nosso tao amado comand linux (Se voce è enbgenheiro de dados e nao manja de linux, tenho minhas duvidas sobre voce - ahhahahhahaha)
Sem mais delongas, vamos executar de forma manual
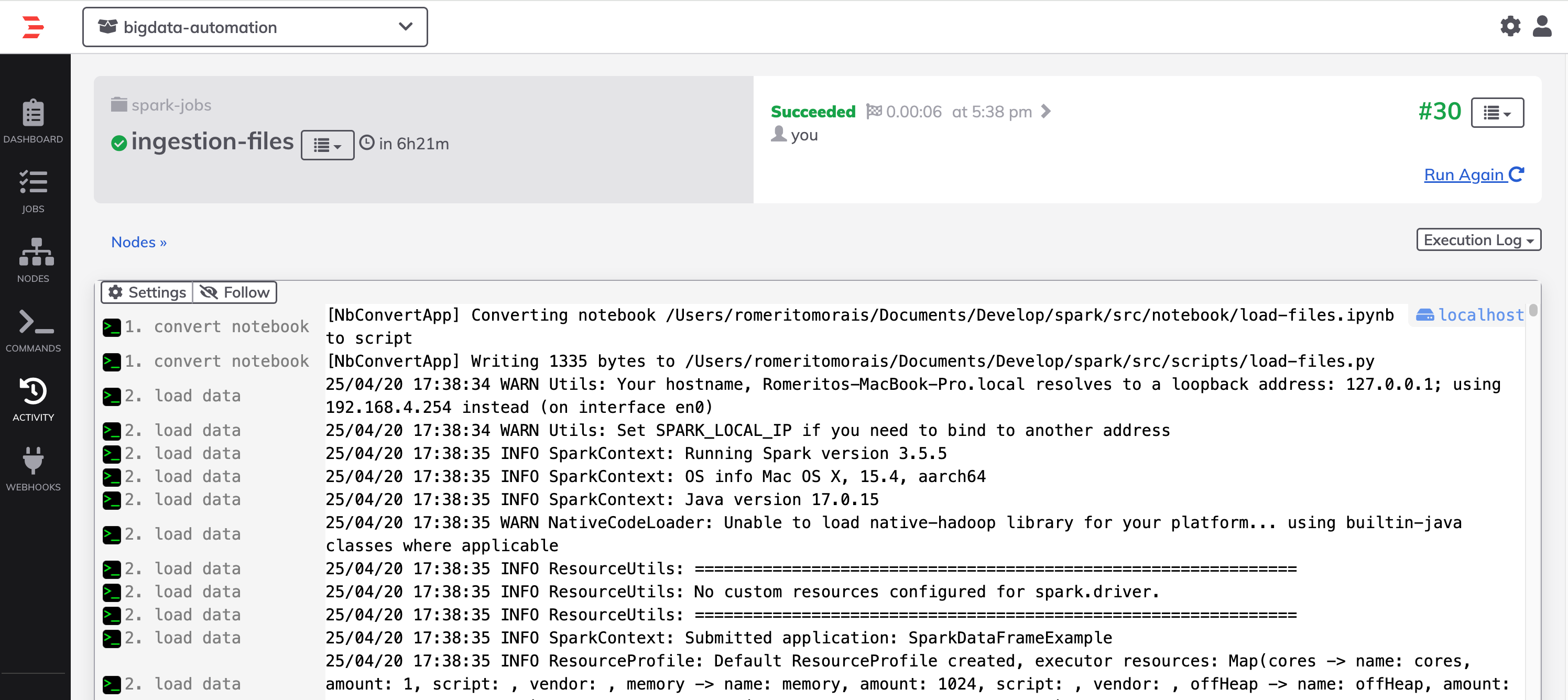
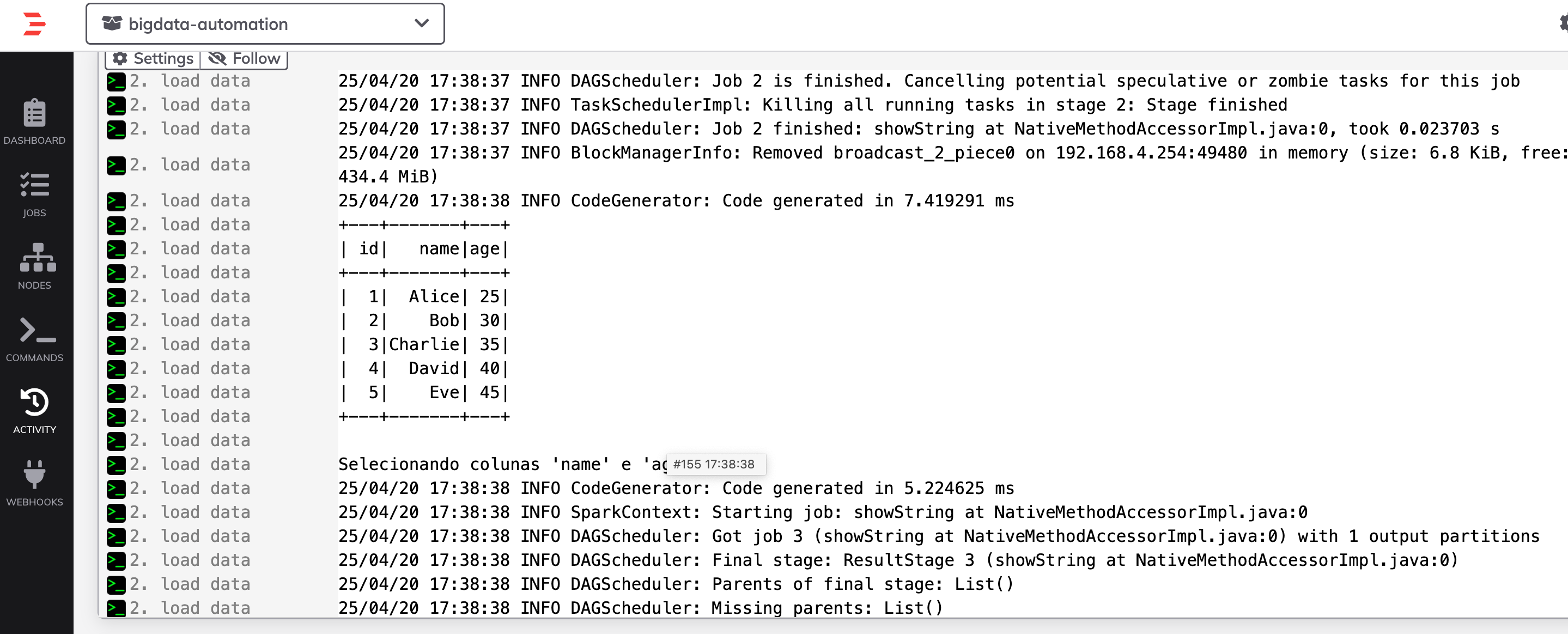
Olha que legal, spark processou com sucesso e via SPARK-SUBMIT
Rundeck è simplismente incrivel, tem muito recurso legal, veja:
✅ Execução de jobs manuais ou agendados
🗂️ Organização por projetos
🔄 Workflows com múltiplos passos
🧩 Suporte a plugins e integrações (Ansible, Jenkins, Docker, etc.)
🔐 Controle de acesso via ACLs e LDAP/AD
🔁 Execução em múltiplos nós/servidores
⏰ Agendamento com cron
📢 Notificações (email, Slack, Webhook)
📜 Logs detalhados de execução
🔍 API REST para integração
🧭 Descoberta de inventário de nós
🖥️ Interface web intuitiva
🏢 Recursos enterprise (HA, RBAC avançado, integração com ITSM)
Somente isso acima ja da uma pisa no Airflow. FUI!!!