
Executando o Jupyter Notebook (local) em Cluster Databricks
Faz tempos que não posto nada por aqui, mas vamos lá. A brincadeira de hoje é escrever no jupyter notebook e executar em um cluster remoto…


Faz tempos que não posto nada por aqui, mas vamos lá. A brincadeira de hoje é escrever no jupyter notebook e executar em um cluster remoto do databricks, sei que a maioria instala o spark e executa local, mas quando a configuração da máquina não ajuda, não tem muito o que fazer, acredito que essa seja uma ótima alternativa. Primeiro tu precisa criar um cluster no databricks, e como é de costume siga as imagens.
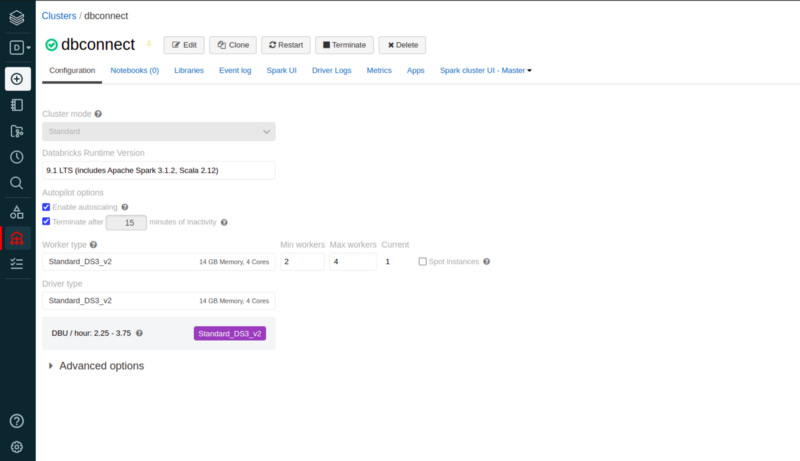
Criei um cluster bem básico, repare que dentre outras configurações deixei marcado a opção terminate after = 15 após 15 minutos sem atividade no cluster ele se auto desliga. Agora vamos para as configurações na nossa máquina local, como sempre vamos usar o linux e para isso precisamos instalar a lib databricks-connect.

Um ponto importante, tu precisa instalar a versão que seja a mesma versão do runtime do seu cluster databricks, no meu caso o runtime = 9.1 LTS, caso contrário podem haver incompatibilidades.
Após a instalação vamos as configurações. No terminal digite: databricks-connect configure
agora insira a url do seu workspace
exemplo: https://adb-00000000000000.11.azuredatabricks.net/
[enter]
token: esse cara tu pode criar assim, vai em: Settings/User Settings vai na opção Generate new token, coloque um nome e periodo de validade depois click em Generate.
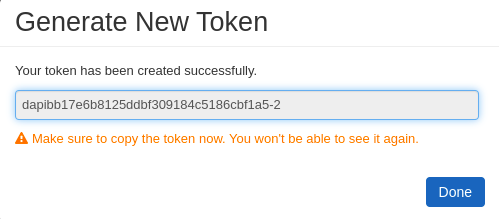
No campo token adicione esse valor gerado.
[enter]
Cluster ID: tu pega ele assim, vai onde o cluster foi criado e click em cima dele, agora olha a url acima, localize onde esteja parecido com isso: https://adb-00000000000000.11.azuredatabricks.net/?o=666632254488975#setting/clusters/1111–000000-gh2g9c4x/configuration
111–000000-gh2g9c4x esse é nosso CLuster ID de
[enter]
Quanto ao restante das configurações tu vai apenas pressionando o
[enter] até finalizar.
Para se certificar que tudo deu certo rode o comando: databricks-connect test e espera concluir.
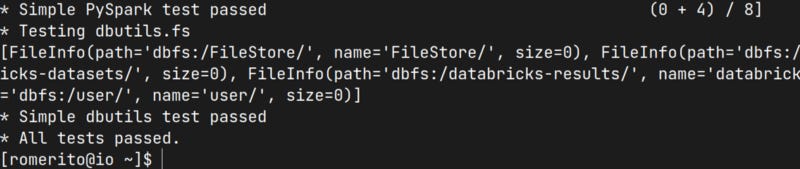
Prontinho, Simple PySpark test passed
lindo. Agora vamos testar um código qualque no nosso cluster databricks, para isso vou usar o jupyter notebook dentro do vscode.
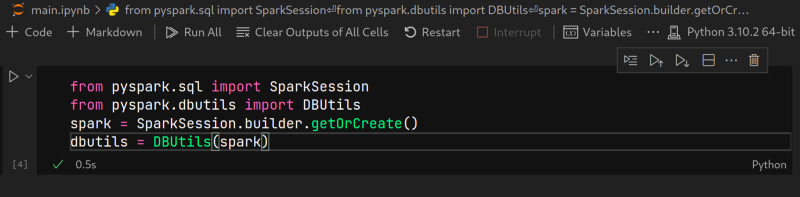

O comando do dbutils listou o meu diretório no databricks, o que significa que ja tá funcional, vou carregar o dataset apps.csv
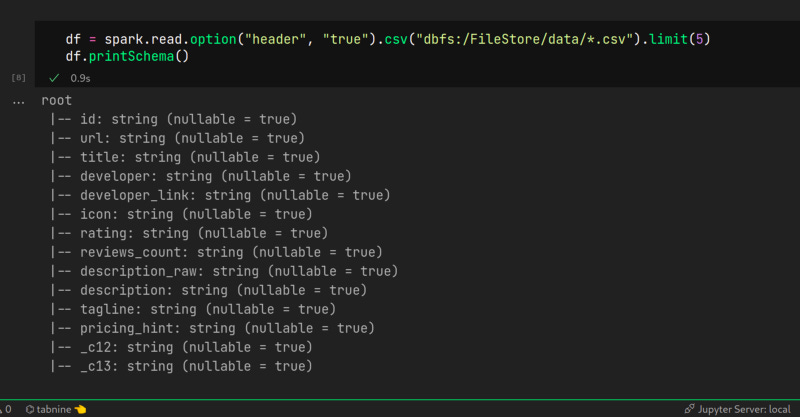
lindo não!? e para finalizar vou gravar no database default, perceba que não tenho tabela alguma no banco de dados
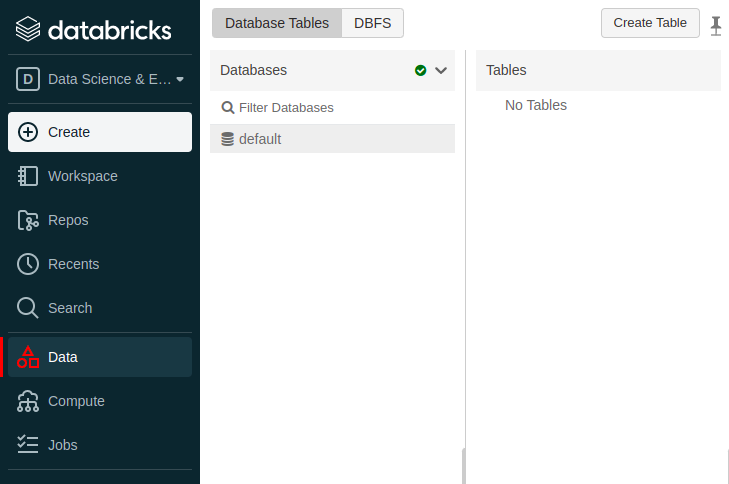
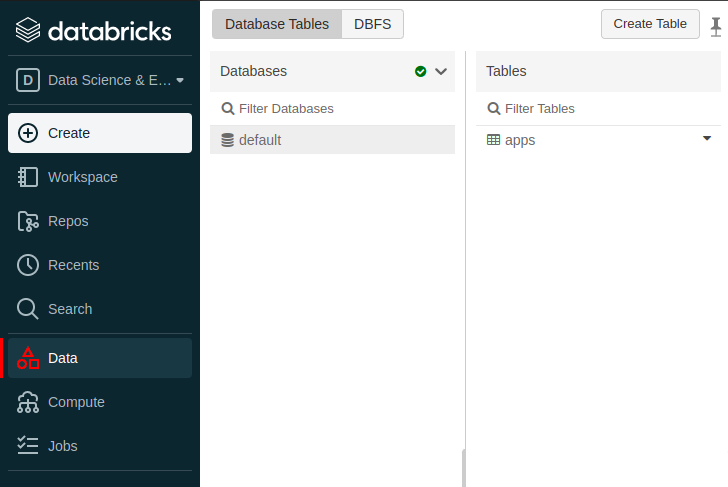
e agora play

resultado
e para de fato mostrar de onde executamos os comandos, veja o campo da descrição da imagem abaixo.
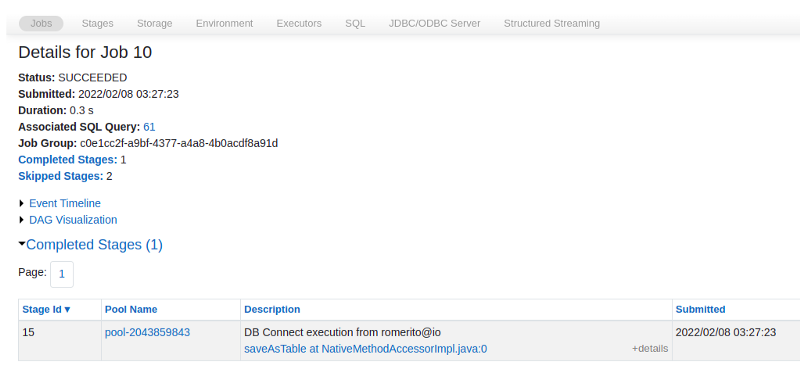
Isso mesmo, o comando partiu de romerito@io meu terminal.
Espero que tenham curtido, esse tutorial foi retirado do artigo original
https://docs.microsoft.com/pt-br/azure/databricks/dev-tools/databricks-connect